
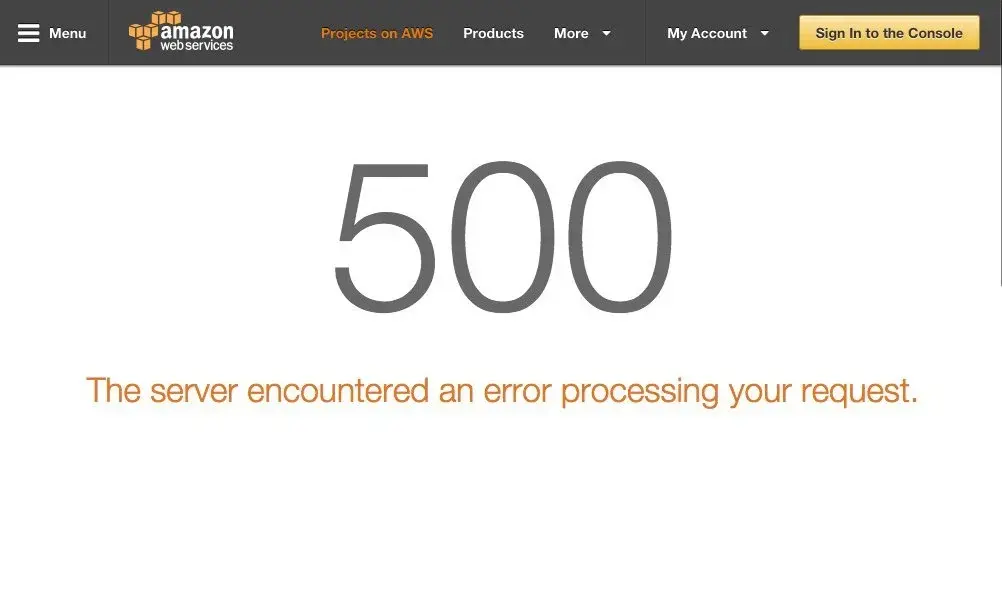
Online service reliability is crucial in the digital age. Even robust systems can face unexpected outages, affecting various platforms. Let’s explore the insights!
Are there any major outages that you remember?
No, but this is why we think centralising the operations of the internet isn’t a good idea. The web was meant to be decentralised and federated, yet it has become centralised and has mostly a few walled gardens.
The fediverse and matrix etc may not be perfect, but technically they are some of the better ideas in terms of ensuring if one server or even quite a few servers go down the whole of a network/service doesn’t.
The Downtime Project is a pretty interesting podcast that covers some large outages and discusses their post-mortem analysises. Worth a listen IMO, very interesting stuff and some good lessons to learn.
That one time cocoa pods (a dependency management system for iOS development) was essentially doing a DDNS when their spec repo was using GitHub as a CDN. https://blog.cocoapods.org/Master-Spec-Repo-Rate-Limiting-Post-Mortem/
Microsoft/Crowdstrike last summer.
In 2022, Gmail was down for about 6 hours.
My VPS provider had an outage a few months back, for a few hours. Luckily there was nothing big running on my server, only a discord bot, 6tunnel and my wip website.
Going beyond “that you remember”, Wikipedia has a list.


{kind=link}