
lemmy_server PostgreSQL table for comment does not keep parent comment id directly, it uses a path field of ltree type.
by default, every comment has a path of it’s own primary key id.
comment id 101, path = “0.101”
comment id 102, path = “0.102”
comment id 103, path = “0.101.103”
comment id 104, path = “0.101.103.104”
comment 103 is a reply to comment 101, 104 is a reply to 103.
A second table named comment_aggregates has a count field with comment_id column linking to comment table id key. On each new comment reply, lemmy_server issues an update statement to update the counts on every parent in the tree. Rust code issues this to PostgreSQL:
if let Some(parent_id) = parent_id {
let top_parent = format!("0.{}", parent_id);
let update_child_count_stmt = format!(
"
update comment_aggregates ca set child_count = c.child_count
from (
select c.id, c.path, count(c2.id) as child_count from comment c
join comment c2 on c2.path <@ c.path and c2.path != c.path
and c.path <@ '{top_parent}'
group by c.id
) as c
where ca.comment_id = c.id"
);
sql_query(update_child_count_stmt).execute(conn).await?;
}
I’ve been playing with doing bulk INSERT of thousands of comments at once to test SELECT query performance.
So far, this is the only SQL statement I have found that does a mass UPDATE of child_count from path for the entire comment table:
UPDATE
comment_aggregates ca
SET
child_count = c2.child_count
FROM (
SELECT
c.id,
c.path,
count(c2.id) AS child_count
FROM
comment c
LEFT JOIN comment c2 ON c2.path <@ c.path
AND c2.path != c.path
GROUP BY
c.id) AS c2
WHERE
ca.comment_id = c2.id;
There are 1 to 2 millions comments stored on lemmy.ml and lemmy.world - this rebuild of child_count can take hours, and may not complete at all. Even on 100,000 rows in a test system, it’s a harsh UPDATE statement to execute. EDIT: I found my API connection to production server was timing out and the run-time on the total rebuild isn’t as bad as I thought. With my testing system I’m also finding it is taking under 19 seconds with 312684 comments. The query does seem to execute and run normal, not stuck.
Anyone have suggestions on how to improve this and help make Lemmy PostgreSQL servers more efficient?
EDIT: lemmy 0.18.3 and 0.18.4 are munging the less-than and greater-than signs in these code blocks.
show
EXPLAINfor the query, maybe alsoEXPLAIN (ANALYZE, BUFFERS)with sayLIMIT 1000so that it finishes some daySo it turns out that the query was finishing within minutes and the API gateway was timing out. Too many Lemmy SQL statements in my head. On a test system update of all the comment second run just took under 17 seconds for 313617 rows that has some decent reply depth, so it isn’t as bad as I thought.
Wuff… I’m no expert, but this looks like the materialized path pattern, which expressly sacrifices write perf for lookup perf. I’ve used it in the past for managing, say, an e-commerce site product category taxonomy - something that isn’t going to change very often, but liable to get hammered with reads.
I can’t say what might improve this without more research, but I can tell you that this type of pattern isn’t supposed to be performant on write.
DISCLAIMER: I’ve never looked at lemmy’s code base. 🤦♂️
I think no matter any possible optimisation to the query (if any), the current design may not be going to scale very well given it traverses all the
comment X commentspace every time a comment is added.To my mind, it works well when there are many shallow comments (ie little nesting/threading) which might not be the best strategy for the content lemmy serves.
Can you share the structures of
comment_aggregatesandcomment? I feel there’s a good opportunity for denormalisation there which may mean better performance.That said, here’s one concrete idea that crossed my mind and could be worth benchmarking:
- Create an
AFTER UPDATEtrigger oncomment_aggregateswhich updates a comment’s immediate parent(s)child_count(basically increment it by 1.) - Re-write the posted query to only update the immediate parents of the comment being added.
That results in the trigger being run exactly
mtimes wheremis the number of comments of the subtree where the new comment was just added to.Does that make sense?
given it traverses all the comment X comment space every time a comment is added.
The second query I shared is only referenced for maintenance rebuild. The routine update of count does target only the tree that the reply is to:
select c.id, c.path, count(c2.id) as child_count from comment c join comment c2 on c2.path <@ c.path and c2.path != c.path and c.path <@ '0.1' group by c.idI found a particularly complex tree with 300 comments. In production database (with generated test data added for this particular comment tree), it is taking .371 seconds every time a new comment is added, here is the result of the SELECT pulled out without the UPDATE:
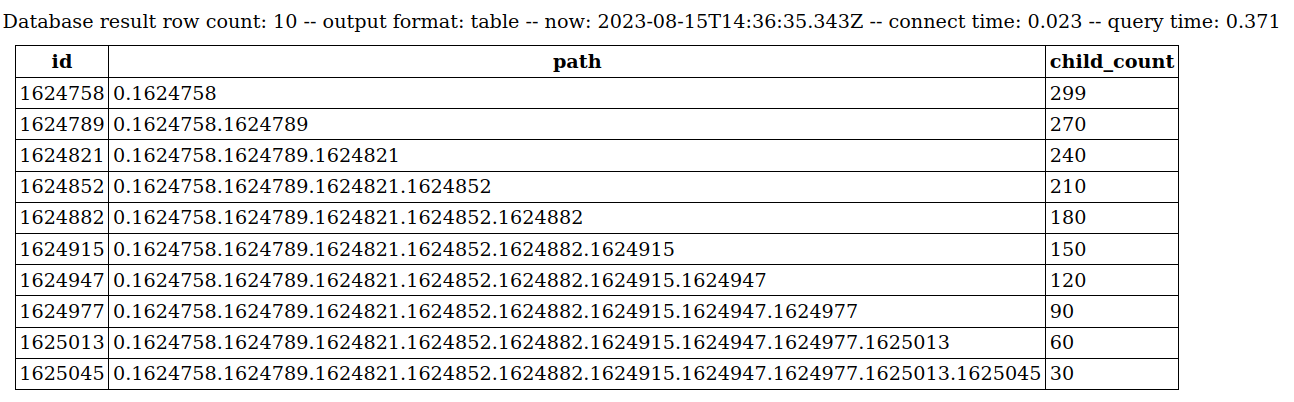
Obviously with the UPDATE it will take longer than .371 seconds to execute.
First off, IIRC,
COUNT(*)used to be slightly faster (~10-15%) thanCOUNT(some_column)in PG. There’s a chance that recent versions of PG have fixed this inconsistency but still worth benchmarking.
Now to the query:
To my mind, we’ve already got
comment_aggregatewhich is supposed to store the result of the query shared above, right? Why do we need to run thatSELECTagain instead of simply:-- pseudo-code SELECT ca.id, ca.child_count, ca.path FROM comment_aggregate ca WHERE ca.post_id = :post_idI think I’m confusing matters here b/c I don’t know lemmy’s DB structure. Is there a link to an ERD/SQL/… you could share so I could take a look and leave more educated replies?
I agree there is potential to reuse the child_count from child/grandchild rows. But there has to be some sense to the order they are updated in so that the deepest child gets count updated first?
potential to reuse
I have a feeling that it’s going to make a noticeable difference; it’s way cheaper than a
JOIN ... GROUP BYquery.
order they are updated in so that the deepest child gets count updated first
Given the declarative nature of SQL, I’m afraid that’s not possible - at least to my knowledge.
But worry not! That’s why there are stored procedures in almost every RDBMS; to add an imperative flare to the engine.
In purely technical terms, Implementing what you’re thinking about is rather straight-forward in a stored procedure using a
CURSOR. This could be possibly the quickest win (plus the idea ofCOUNT(*)if applicable.)
Now, I’d like to suggest a possibly longer route which I think may be more scalable. The idea is based around the fact that comments themselves are utterly more important than the number of child comments.
- The first priority should be to ensure
INSERT/UPDATE/SELECTare super quick oncommentandpost. - The second priority should be to ensure
child_countis eventually correctly updated when (1) happens. - The last priority should be to try to make (2) as fast as we can while making sure (3) doesn’t interfere w/ (1) and (2) performance.
Before rambling on, I’d like to ask if you think the priorities make sense? If they do, I can elaborate on the implementation.
How did it go @RoundSparrow@lemmy.ml? Any breakthroughs/
I found the total table update wasn’t as bad performing as I thought and the API gateway was timing out. I’m still generating larger amounts of test data to see how it performs in edge worst-case situations.
Can you keep this thread posted please? Or you can share a PR link so I can follow up the progress there. Am very interested.
- The first priority should be to ensure
- Create an
