


5·
21 days ago“businesses and employees”
the business pays for it, the employees “use” it.
the business measures the value by how many employees they can remove.
if the business is measuring “productivity”, how are they doing that? Is it jira tickets? Is it timesheets? are they measuring quality? Is it starting to seem like you’re trying to pick up water with your fingers?
if you pretend that ai ceos are actually doing marketing the trajectory is right there staring you in the face







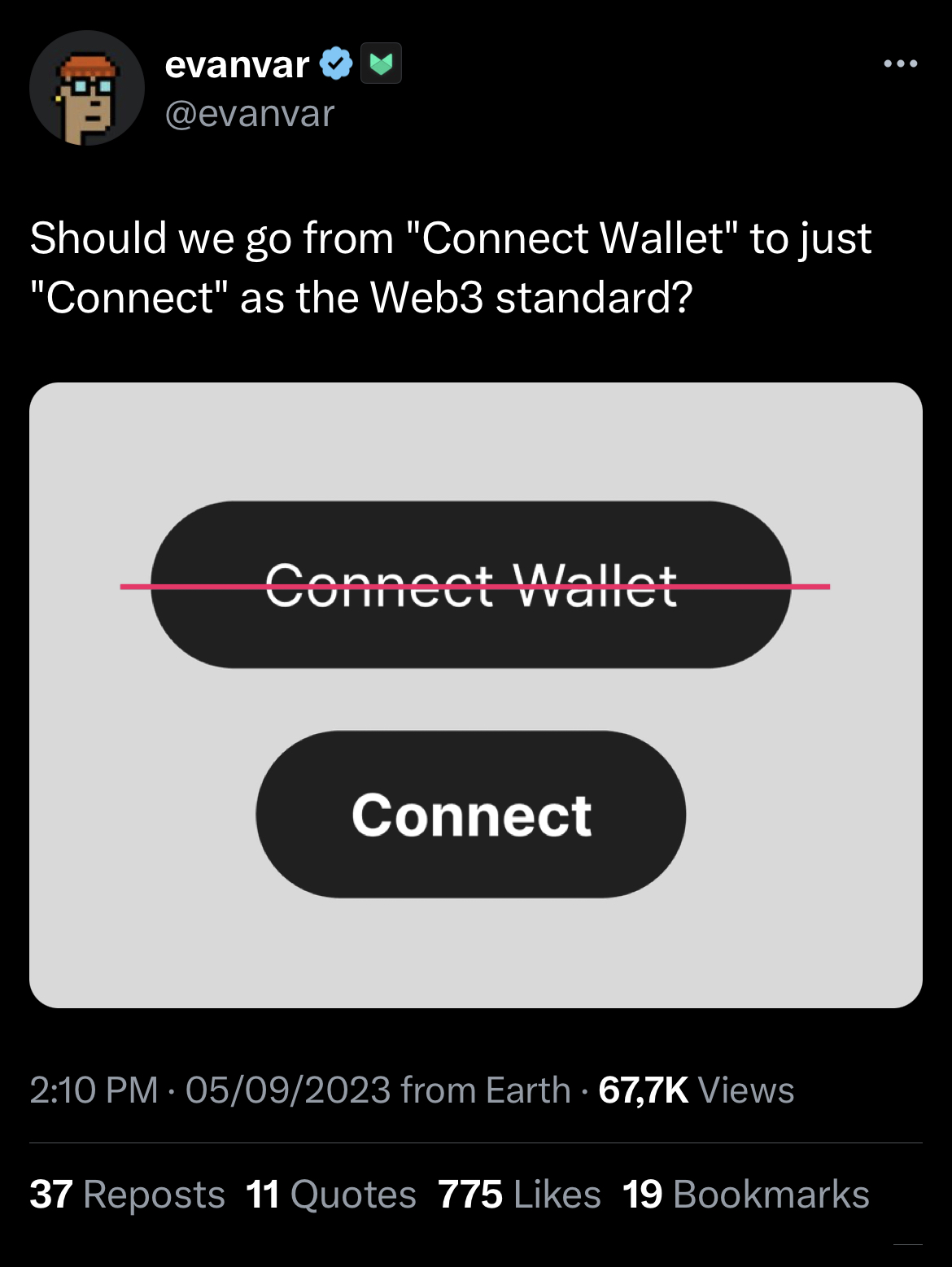{kind=link}
{kind=link}
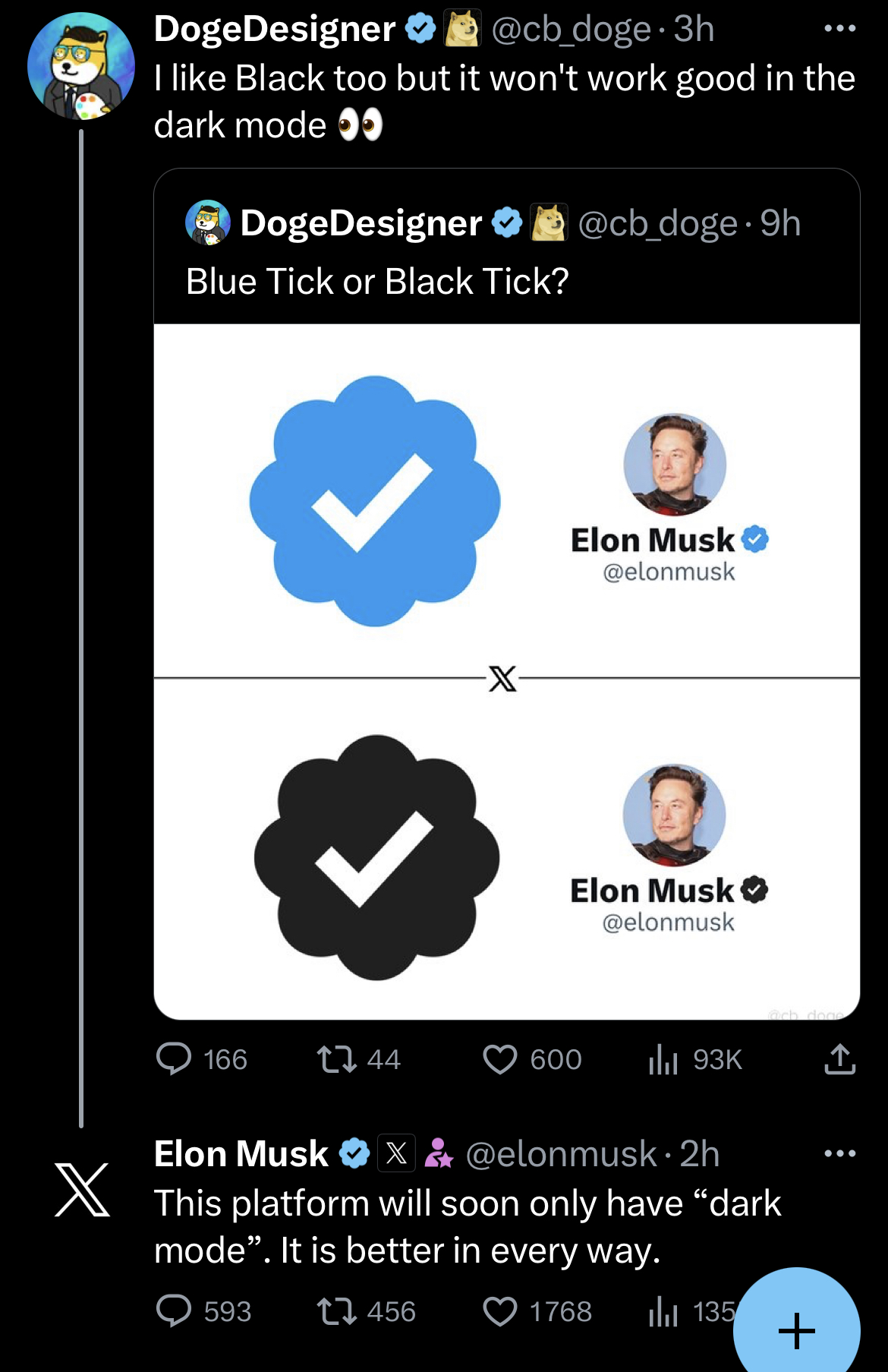{kind=link}
{kind=link}
My new video about the anti-design of the tech industry where I talk about this little passage from an ACM article that set me off when I found it a few years back.
In short, before software started eating all the stuff “design” meant something. It described a process of finding the best way to satisfy a purpose. It was a response to the purpose.
The tech industry takes computation as being an immutable means and finds purposes it may satisfy. The purpose is a response to the tech.
p.s. sorry to spam. :)
vid: https://www.youtube.com/watch?v=ollyMSWSWOY pod: https://pnc.st/s/faster-and-worse/8ffce464/tech-as-anti-design
threads bsky: https://bsky.app/profile/fasterandworse.com/post/3ltwles4hkk2t masto: https://hci.social/@fasterandworse/114852024025529148