
Hello,
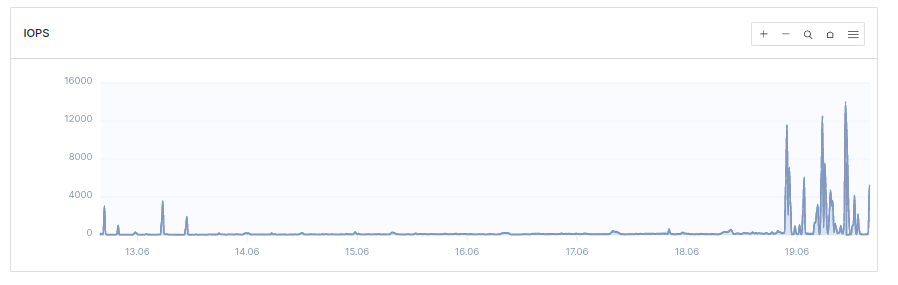
In the last 24 hours my instance has been experiencing spikes in CPU usage. During these spikes, the instance is unreachable.

The spikes are not correlated with an increase in bandwidth use. They are strongly correlated with IOPS spikes, specifically with read operations.
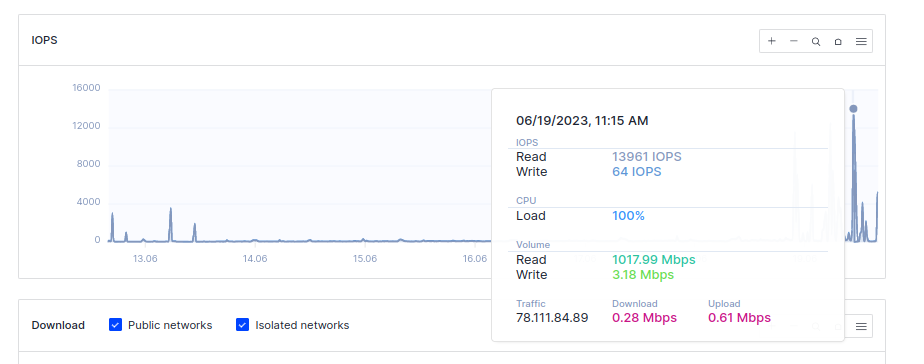
Analysis of htop during these spikes shows /app/lemmy and the postgres database UPDATE operation as the potential culprits, with the postgres UPDATE being my main suspicion.
Looking through the postgres logs at the time of these spikes, I think that this block may be associated with these spikes:
spoiler
2023-06-19 14:28:51.137 UTC [1908] STATEMENT: SELECT "comment"."id", "comment"."creator_id", "comment"."post_id", "comment"."content", "comment"."removed", "comment"."published", "comment"."updated", "comment"."deleted", "comment"."ap_id", "comment"."local", "comment"."path", "comment"."distinguished", "comment"."language_id", "person"."id", "person"."name", "person"."display_name", "person"."avatar", "person"."banned", "person"."published", "person"."updated", "person"."actor_id", "person"."bio", "person"."local", "person"."banner", "person"."deleted", "person"."inbox_url", "person"."shared_inbox_url", "person"."matrix_user_id", "person"."admin", "person"."bot_account", "person"."ban_expires", "person"."instance_id", "post"."id", "post"."name", "post"."url", "post"."body", "post"."creator_id", "post"."community_id", "post"."removed", "post"."locked", "post"."published", "post"."updated", "post"."deleted", "post"."nsfw", "post"."embed_title", "post"."embed_description", "post"."embed_video_url", "post"."thumbnail_url", "post"."ap_id", "post"."local", "post"."language_id", "post"."featured_community", "post"."featured_local", "community"."id", "community"."name", "community"."title", "community"."description", "community"."removed", "community"."published", "community"."updated", "community"."deleted", "community"."nsfw", "community"."actor_id", "community"."local", "community"."icon", "community"."banner", "community"."hidden", "community"."posting_restricted_to_mods", "community"."instance_id", "comment_aggregates"."id", "comment_aggregates"."comment_id", "comment_aggregates"."score", "comment_aggregates"."upvotes", "comment_aggregates"."downvotes", "comment_aggregates"."published", "comment_aggregates"."child_count", "comment_aggregates"."hot_rank", "community_person_ban"."id", "community_person_ban"."community_id", "community_person_ban"."person_id", "community_person_ban"."published", "community_person_ban"."expires", "community_follower"."id", "community_follower"."community_id", "community_follower"."person_id", "community_follower"."published", "community_follower"."pending", "comment_saved"."id", "comment_saved"."comment_id", "comment_saved"."person_id", "comment_saved"."published", "person_block"."id", "person_block"."person_id", "person_block"."target_id", "person_block"."published", "comment_like"."score" FROM ((((((((((("comment" INNER JOIN "person" ON ("comment"."creator_id" = "person"."id")) INNER JOIN "post" ON ("comment"."post_id" = "post"."id")) INNER JOIN "community" ON ("post"."community_id" = "community"."id")) INNER JOIN "comment_aggregates" ON ("comment_aggregates"."comment_id" = "comment"."id")) LEFT OUTER JOIN "community_person_ban" ON ((("community"."id" = "community_person_ban"."community_id") AND ("community_person_ban"."person_id" = "comment"."creator_id")) AND (("community_person_ban"."expires" IS NULL) OR ("community_person_ban"."expires" > CURRENT_TIMESTAMP)))) LEFT OUTER JOIN "community_follower" ON (("post"."community_id" = "community_follower"."community_id") AND ("community_follower"."person_id" = $1))) LEFT OUTER JOIN "comment_saved" ON (("comment"."id" = "comment_saved"."comment_id") AND ("comment_saved"."person_id" = $2))) LEFT OUTER JOIN "person_block" ON (("comment"."creator_id" = "person_block"."target_id") AND ("person_block"."person_id" = $3))) LEFT OUTER JOIN "community_block" ON (("community"."id" = "community_block"."community_id") AND ("community_block"."person_id" = $4))) LEFT OUTER JOIN "comment_like" ON (("comment"."id" = "comment_like"."comment_id") AND ("comment_like"."person_id" = $5))) LEFT OUTER JOIN "local_user_language" ON (("comment"."language_id" = "local_user_language"."language_id") AND ("local_user_language"."local_user_id" = $6))) WHERE (((((("community"."hidden" = $7) OR ("community_follower"."person_id" = $8)) AND ("local_user_language"."language_id" IS NOT NULL)) AND ("community_block"."person_id" IS NULL)) AND ("person_block"."person_id" IS NULL)) AND (nlevel("comment"."path") <= $9)) ORDER BY subpath("comment"."path", $10, $11), "comment_aggregates"."hot_rank" DESC LIMIT $12 OFFSET $13
2023-06-19 14:28:51.157 UTC [1] LOG: background worker "parallel worker" (PID 1907) exited with exit code 1
2023-06-19 14:28:51.246 UTC [1] LOG: background worker "parallel worker" (PID 1908) exited with exit code 1
2023-06-19 14:28:55.228 UTC [48] ERROR: could not resize shared memory segment "/PostgreSQL.3267719818" to 8388608 bytes: No space left on device
Has anyone else faced this issue? One idea is that the database has grown to the point that my VPS does not have enough CPU resources to handle a common routine operation… But that does not explain to me the sudden appearance of the spikes - I would have expected a gradual increase in the size of the spikes over time.
ERROR: could not resize shared memory segment “/PostgreSQL.3267719818” to 8388608 bytes: No space left on device
Is your disk full?
No, the disk is about 30% full. I think that this message is about the RAM being full. I am thinking that holding the table in memory is taking up all of the ram - but I don’t see why this started happening in the last day so suddenly.
An explanation may be that if the RAM is not depleted during the operation, whatever causes the CPU spikes is not triggered. As the database grew to the point that it takes over 2 GB to hold this table in RAM, it is this filling-up of the RAM that somehow causes the CPU spikes. In this case, I can resolve the problem by increasing the available RAM… However, I would like to make sure that this is really the problem before increasing the RAM.
I suppose an easy way to test is to increase the RAM to 3GB and see if the spikes stop… I’m going to that now.
The spikes disappeared after I increased the RAM from 2 GB to 3 GB, and they have not re-appeared over the past few hours.

It appears like some some process was hitting the 2GB RAM limit - even though under normal use only about 800GB of RAM are allocated. At first I thought that the high amount of read IOPS might be due to the swap memory kicking into action, but the server has no allocated swap.
The postgresql container appears to fail when all of the RAM is used up, and it may be that the high CPU usage is somehow related to repopulating the dabase as it is restarted… But I would think that if this were the case I would see similar spikes whenever I reboot - and I don’t.
Conclusion: I am not sure why this happens.
But if anyone else notices these spikes it may be a RAM issue. Try increasing the RAM and see if they go away.
I’m on Linux with no swap, and can experience CPU spikes when running out of RAM. The 100% CPU usage is illusory - the CPU isn’t actually doing any calculations. When I tried using a profiler at such time, 100% of the CPU usage was something like “waiting on input/output”, which htop counts as usage.
Why is it doing input/output? Linux has a “feature” where under memory starvation it evicts pages of executable code (like shared libraries) from memory, because it knows it can load them from disk when needed. But what turns out happening instead is that the kernel will run one line of code from one thread, evict everything, load the code and shared libraries for the other thread from disk (takes loooong time!), run one line of code, evict everything, switch/repeat… This leads to disk thrashing (when we still had disks) and makes system unusable.
Is there any way, like via config or command line options, to set a hard limit on PostgreSQL memory usage, such that it would guarantee not to consume more than 1.5GB, say? Barring that (or adding more RAM indefinitely), look into the “OOM-killer” Linux feature. There is some way to configure the “ferocity” level of the watchdog inside the kernel so that it kills the process with the largest memory consumption sooner, instead of trying to thrash around by evicting even more shared memory. That will kill the Postgress process and force it to restart, but you say it works fine normally at around 0.8GB? Then the spike of runaway memory consumption is either a bug/memory leak, or a rare special event like rearranging/compressing the database somehow.
