Fully agree, overfitting might be an issue. We don’t know how much training data was available. Just more than the first assumption suggests. But it might still not be enough.
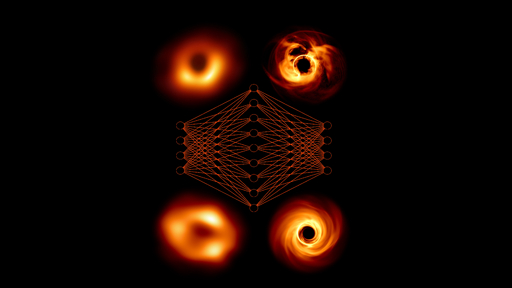
Oh, they don’t train on image data. They train on raw sensor data. And as mentioned earlier, they used all the data that was too noisy to produce images out of it.
9 petabytes of raw data have been produced with the EHT in 2017 and 2018. After filtering, only about 100 terabytes were left. After final calibrations, about 150 gigabytes were then used to generate the images.
So clearly a lot of data was thrown away, as it was not usable for generating images. However, a machine learning model might be able to use this data.

Fully agree, overfitting might be an issue. We don’t know how much training data was available. Just more than the first assumption suggests. But it might still not be enough.
There aren’t a lot of high resolution images of black holes. I know of one. So not a lot.
Oh, they don’t train on image data. They train on raw sensor data. And as mentioned earlier, they used all the data that was too noisy to produce images out of it.
Of that one mission, right? Until you have thousands of these days sets, it’s the wrong approach.
9 petabytes of raw data have been produced with the EHT in 2017 and 2018. After filtering, only about 100 terabytes were left. After final calibrations, about 150 gigabytes were then used to generate the images.
So clearly a lot of data was thrown away, as it was not usable for generating images. However, a machine learning model might be able to use this data.
It’s still only one black hole. It’s one huge datapoint.