
I’m pretty new to selfhosting, but one thing that I know to take seriously is log collection. Since there are a lot of different type of logs (kernel log, application logs, etc) and logs come in many different formats (binary, json, strings) - it’s no easy task to collect them centrally and look through them whenever neccessarly.
I’ve looked at grafana and tried the agent briefly, but it wasn’t as easy as I thought (and it might be a too big tool for my needs). So I thought to ask the linuxlemmy community to get some inspiration.
You must log in or register to comment.
Nothing. I always use the standard configuration from the services I’ve installed. If something doesn’t work I go into those logs and look what’s wrong.
Heh. Kickin’ it old skool. Nice.
Honestly? I just ignore them. Something seems to be happening to them, as they’re not growing infinitely, but no idea why.
It was a bit complicated to set this up, but it took me almost no time at all.
For a bit enhanced log file viewing, you could use something like lnav, I think it’s packaged for most distributions.
Cockpit can be useful for journald, but personally I think GUI stuff is a bit clunky for logs.
Grep, awk and sed are powerful tools, even with only basic knowledge of them. Vim in readonly mode is actually quite effective for single files too.
For aggregating multiple servers’ logs good ol’ rsyslog is good, but not simple to set up. There are tutorials online.
Holy guacamole this (edit: lnav) is pretty good! Probably does not solve collection of logs from multiple systems, but for local inspection (or after having files copied elsewhere) it seems to be a real powertool
Rsyslog to collect logs to a single server, then lnav for viewing them on that server is a good combo. Oldschool but very effective for self-host scale.
Glad the tip was useful!
I’ve just started digging into it myself ! Here’s my current setup (I’ll see how it scales in the long term):
- syslog on every host
- Telegraf collects and parse logs
- InfluxDB stores everything
- Grafana for dashboards
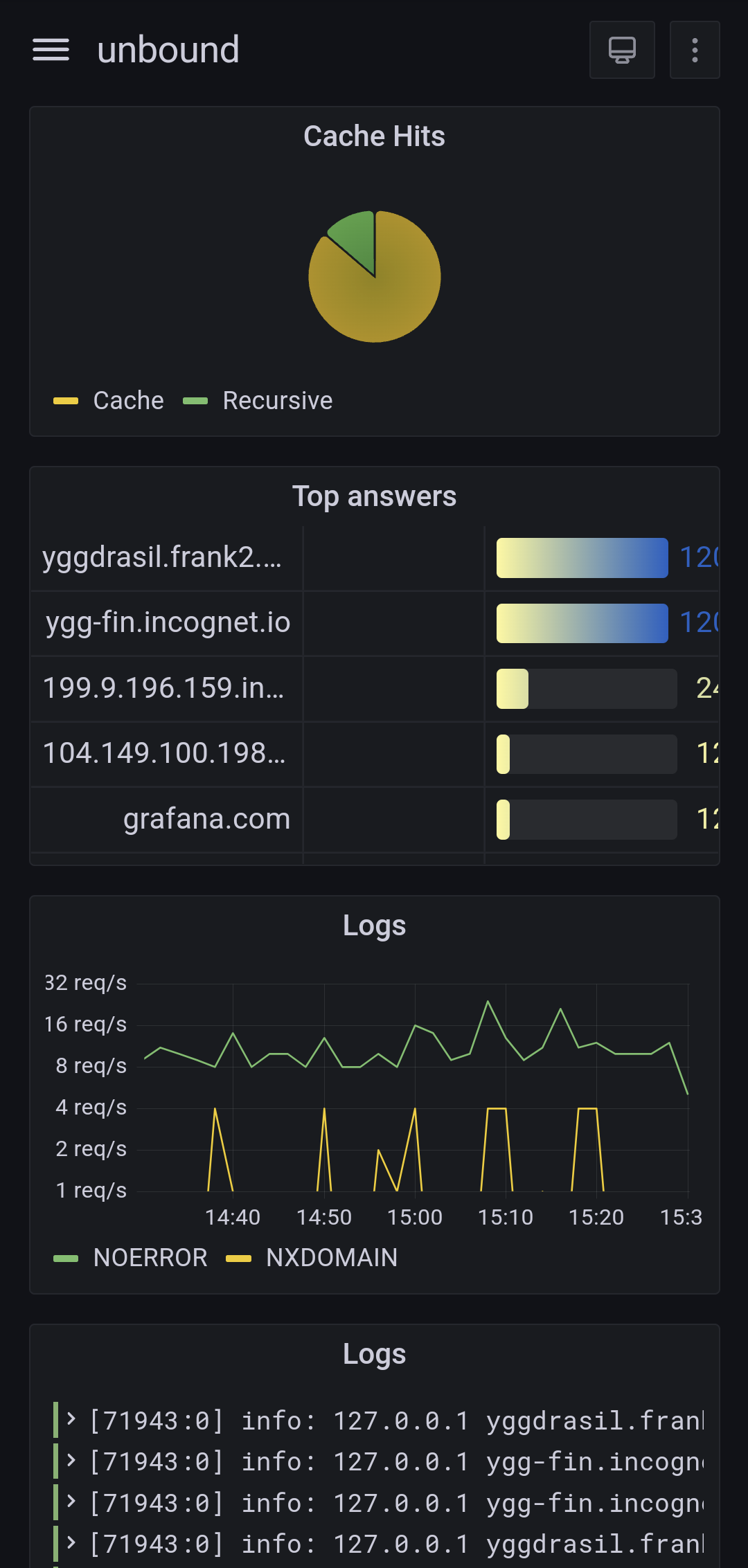
I run OpenBSD on all my servers, and configure all the services to log via syslog.
Then I configuré syslog to send only those I care about (https, DNS, …) to a central telegraf instance, using the syslog protocol (RFC3164).
On this collector, telegraf gets all these logs and parse them using custom grok patterns I’m currently building, to make sense out of every log line it receives. The parsed logs are in turns stored in Influxdb, running on the same host.
I then use Grafana to query InfluxDB and create dashboards out of these logs. Grafana can also display the logs “as-is” so you can search through them (it’s not ideal though as you simply search by regex from the full message, so it’s on par with grep at least).
This setup is fairly new and seem to work very well. Telegraf is also very low on resource usage for now. I’ll have to continue adding grok patterns and send more application logs to it to see how it handles the load. I do have a few questions still unanswered for now, but time will tell:
Q: Should I first collect via a central syslog before sending to telegraf ?
This would let syslog archive all logs in plain text, rotate and compress them. I would also only have a single host to configure for sending logs to telegraf. However this would eat up space, and could hide the original sending hostname for each log. I might try that someday.Q: Should I run telegraf on each host ?
This would distribute the load of the grok parsing amongst all hosts, and then all telegraf processes will send directly to the central one for collection, or even directly into influxdb. I would also benefit from telegraf being install on each host to collect more data (CPU, network stats, …). However it makes the configuration more complex to handle.Q: What is a good retention period ?
For now, influxDB doesn’t expire any data, as I don’t have much yet. In the long run, I should probably delete old data, but it’s hard to tell what is “old” in my case.Q: Do I need an interface to read logs ?
I use this setup mostly for graphs, as grafana can make sense of fields like “http_verb”, “http_code” and such. However, it is much more practical for me to dig into the logs right on the server, in/var/log. Having an interface like chronograf or graylog seems practical, but I feel like it’s overdoing it.Bonus:
Nice! If you’d write a guide on your setup, I’d be all over it (along with others I’m sure) 😀
You’ll want to check this out: https://www.tumfatig.net/2022/ads-blocking-with-openbsd-unbound8/
That’s the post I took inspiration from for this setup. It does use collectd and custom awk scripts for log ingestion though, where I simply use telegraf.
How is the query performance of influxdb for searches in logs for text keywords?
Instead of Influxdb we are using Solr and it is pretty much instantaneous for searching and ordering no matter how large the data is (couple of hundred gigabytes of logs for now). We use it to provide true real-time search in logs for our support team.
It’s instant as well in my case, but I don’t have a huge amount of logs yet. I’m still figuring out this whole setup and what are it’s strength and weaknesses.
I’m using influxdb 1.8 though (which is old), because that’s the version shipped with openbsd repos. It crashes fairly often when you perform “illegal” operations, which is annoying. Like, the
DELETE FROMcommand only lets you use thetimefield in theWHEREclause. Using any other field would crash the DB. I might recompile it from scratch at some point because it lacks too many features from upstream. But for now, it does a decent job, and is really easy to setup (this was the killer feature for me).
In terms if logging: sys journal does the job for me …
I do run prometheus + grafana for some services but that is mostly for some fancy looking graphics nothing really usefull.
I would recomend you to monitor updates of you apps so you are well informed when und what to update (i just have subsribed to all the diffrent release git rss feeds)
Personally I use Loki to aggregate my logs but I’m probably not the typical selfhoster.
You should first define your needs, if you don’t need logs, then don’t bother with them.
This has been on my radar for a while, and I keep putting it off. How are you liking it?
Grafana’s Loki sounded incredibly useful and performant, with the added benefit of reducing storage requirements significantly under some situations.
It is easier to deal with than the elastic stack, but unless you’re already familiar with log stacks, it is still a bit of a threshold to vet over before it starts paying off.
Syslog (rsyslod) is usually the standard answer for the average sysadmin, but it depends a lot on your needs. A lot of newer loggers output as pure JSON, which offer benefits to readability and more approachable search logic/filters/queries (I’m so tired of regex).
When you start venturing down the road of finding the right way to store and forward the output of logging drivers from Docker containers, as one example, rsyslod starts to feel dated.
The easy answers if you want to throw money at the problem are solutions like Splunk, Datadog, or New Relic. If you don’t want to (and most people wouldn’t), then alternatives certainly exist, but some of them are just as heavy on system resources. Greylog has relative feature parity with Splunk Enterprise, but consumes just as much compute and storage if not more, and I found it to be a much larger pain in the butt to administer and keep running.
The likeliest answer to this problem is Grafana Loki, just based on what I’ve read of its capabilities, but I haven’t had a chance to circle back and test it out. Someone here who has might be able to weigh in and speak to its strengths/weaknesses.
My logs were actually filling up my disk! I edited journald conf and limited them to 500mb . disk is only 10gb for reference
What services were you running and for how long? I ask because I rent a very cheap VPS with 10G disk and I want to prepare for this
You could try deploying an ELK stack and manage log collection using Elastic Agents and integrations, works pretty well for us and, as long as your log is supported by an integration, it’s dead simple to manage
And if you need to take a look at it, you’ll really appreciate the convenience and ability to query.
Systemd does all that for you. Just set a limit in journal.conf
So does syslog; and really well. Logging is just another thing Lennart tried to take over from a working system, that he and Kay half-delivered, and wandered off. See also: nfsroot, fast boots, easy init config, nfs mounts in general, and cron.
OK boomer
I’ve been using Loki and promtail for containers I actually care about aggregating logs for. It’s something relatively new for me but so far the experience has been positive.
Any specific guide you followed?
I’ve done everything from local syslog to various open source and proprietary log pipelines and also worked on a team dedicated to building a custom log-processing pipeline from scratch in a large environment.
One lesson I’ve learned is that no matter how nice that web UI is I still want some kind of CLI access and the equivalent of being able to cat, tail and grep logs. In large environments it won’t be actually tail-ing a logfile but I want something that can produce a live logstream for piping into Unix text (and JSON) processing tools.
Make sure that you have logrotate installed and working, to prevent them from piling up.
You can use rsyslog and rsyslogd for OS log. For app use flat file, collect using ansible. 😂
Well I’m quite interested in msg stack like grafana, but haven’t tried it.
Do you push your logs regularly to a central storage, or do you just SSH into the machines regularly to look at the logs?
If it’s OS log,it’s pushing https://serverfault.com/questions/522341/how-do-i-setup-rsyslog-to-send-all-logs-to-multiple-remote-servers
If it’s laravel/apache, php, then use ansible to pull the log. Or using sentry as I remember. 😂
Not OP, but I push all the logs to one central syslog server.
Greylog






